一、基本概念
Java容器类库的用途是“保存对象”,容器库类分为两个不同的分支。
1.Collection。可以保存一个或多个对象,将其保存为一个序列。Collection又可以细分为List(表),Set(集)和Queue(队列)。List按照插入顺序保存对象,从索引0开始为每一个插入的对象分配一个索引。Set与List类似,但与List不同的是Set中不能有相同的对象。Queue对象产生的顺序通常与元素的插入顺序相同,一般按照先进先出的规则来删除与访问元素。
2.Map。Map(映射表)使用二维数组来保存一组或多组成对的“Key—Value”(键值对)对象,一个Key对应一个Value,你可以用key来查找它所对应的value。与Collection不同的是,Collection使用索引数来来查找索引数对应的对象,而Map使用键对象来查找值对象,其实现了键对象与值对象的映射关系。
二、集合类的框架结构
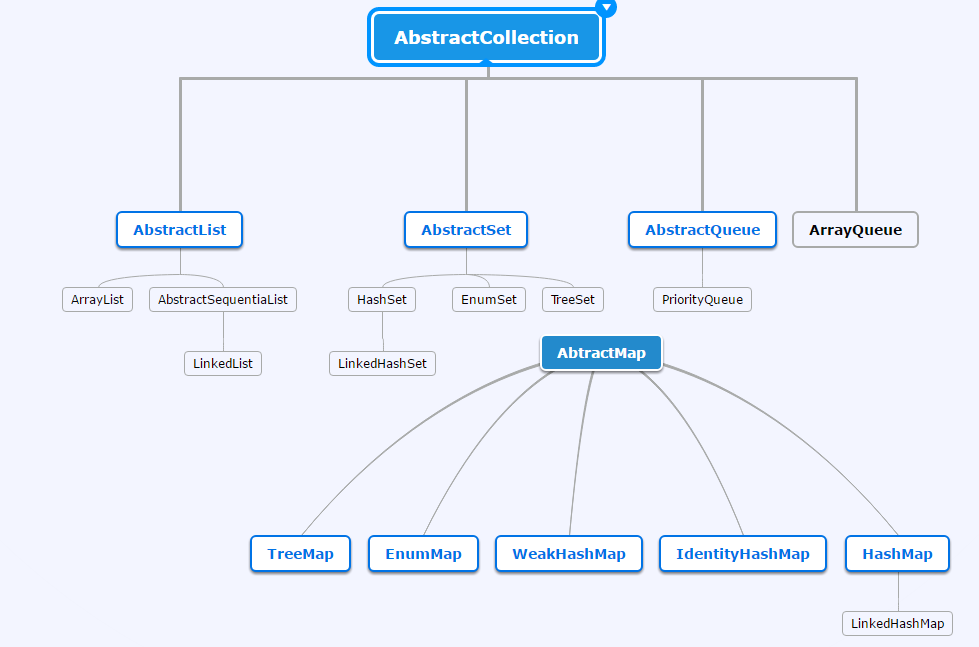
图 1 集合框架中类的继承关系 (部分)
集合框架中类自上而下的的主要继承关系如上图,分别为实现了Collection接口的AbstractCollect类和实现了Map接口的AbstractMap类两大分支。其中较为常用的类有实现了List接口的ArrayList与linkedList类,实现了Set接口的HashSet、TreeSet、LinkedHashSet类,实现了Queue接口的PrioretyQueue类,实现了Map接口的HashMap、LinkedHashMap、TreeMap类等。
(注:这里没有给出类的具体接口实现关系,有关类的具体接口实现关系在后面源码分析的博文中补充)
- ArrayList。ArrayList是一个可以动态增长和缩减的索引序列,其中的元素是未排序的,可以有重复元素。查找元素(指get(int index)方法)的的时间复杂度为O(1),插入和删除元素的时间复杂度为O(n)。查找元素比LinkedList高效,但是插入和删除元素与LinkedList相比较慢。
- LinkedList。LinkedList是一个可以在任何位置快速高效的地插入和删除元素的双向链表,其中的的元素未排序,可以有重复元素。查找元素的时间复杂度为O(n),插入和删除元素的时间复杂度为O(1)。与ArrayList比,查找元素较慢,插入和删除元素较为高效。LinkedList还可以用来实现栈,队列,以及双端队列。
- HashMap。HashMap是一种储存键值对的数据结构,其中的元素未排序,键对象不能重复,值对象可以重复。HashMap其底层数据结构为散列表(数组+链表),若散列函数均匀散列,装填因子合理,查找元素的时间复杂度为O(1),插入和删除的时间复杂度也均为O(1)。若散列表中的某个桶储存的链表长度大于8时,该链表将转化为红黑树,这个桶中元素的查询、插入和删除的时间复杂度将都变为O(log n),n为该桶中的元素个数。
- LinkedHashMap。也是一种储存键值对的映射表,与HashMap不同的是,LinkedHashMap还使用了双向链表来储存元素的插入顺序。
- TreeMap。TreeMap是一种对插入的键值对自动有序排列的映射表。其中的键对象已排序,键对象不能重复,值对象可以重复,插入TreeMap的键对象要实现Comparable或Comparator接口具有排序功能。底层数据结构为红黑树,查询、插入和删除的时间复杂度为O(log n),效率均低于HashMap()。
- HashSet。HashSet是一个不能插入重复元素的集合。其中的元素未排序,没有重复元素。通过阅读源码可知,HashSet是通过HashMap实现的,其查找、插入和删除的时间复杂度也均为O(1)。
- LinkedHashSet。其中的元素未排序,没有重复元素。LinkedHashSet与HashSet不同的是,LinkedHashSet是通过LinkedHashMap实现,所以LinkedHashSet也储存了元素的插入顺序。
- TreeSet。TreeSet是一个没有重复元素的能够对插入元素自动排序的集合。其中的元素已排序,没有重复元素。通过源码可知,HashSet是通过TreeMap实现,所以插入TreeSet的对象要实现Comparable或Comparator接口具有排序功能。底层数据结构为红黑树,查询、插入和删除的时间复杂度为O(log n),效率均低于HashSet()。
- PriorityQueue。PriorityQueue是一种可以高效查询其中最小的元素的集合,底层数据结构为最小堆,没有重复元素。查询最小元素的时间复杂度为O(1),查询其他元素的时间复杂度为O(n),插入和删除的时间复杂度为O(log n)。
(注:以上集合类均不是线程安全的 )
(小官原创,若有谬误,望各位前辈批评指正)